mapreduce 词频统计
本文共 4990 字,大约阅读时间需要 16 分钟。
- 基于八股文的形式编写mapreduce 程序
- 打包jar 与测试运行处理
- wordcount 为例 理解mapreduce 并行计算原理
基于八股文的形式编写mapreduce 程序
mapreduce java 代码
package org.apache.hadoop.studyhdfs.mapredce;import java.io.IOException;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.conf.Configured;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.Reducer;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import org.apache.hadoop.util.Tool;import org.apache.hadoop.util.ToolRunner;/** * * @author zhangyy * */public class WordCountMapReduce extends Configured implements Tool{ // step 1: mapper class /** * public class Mapper */ public static class WordCountMapper extends // Mapper { // map output value private final static IntWritable mapOutputValue = new IntWritable(1) ; // map output key private Text mapOutputKey = new Text(); @Override public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { System.out.println("map-input-key =" + key + " : map-input-value = " + value); // line value String lineValue = value.toString(); // split String[] strs = lineValue.split(" ") ; // iterator for(String str: strs){ // set map output key mapOutputKey.set(str); // output context.write(mapOutputKey, mapOutputValue); } } } // step 2: reducer class /** * public class Reducer */ public static class WordCountReducer extends // Reducer { private IntWritable outputValue = new IntWritable() ; @Override public void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException { // temp: sum int sum = 0 ; // iterator for(IntWritable value: values){ // total sum += value.get() ; } // set output value outputValue.set(sum); // output context.write(key, outputValue); } } // step 3: driver public int run(String[] args) throws Exception { // 1: get configuration// Configuration configuration = new Configuration(); Configuration configuration = super.getConf() ; // 2: create job Job job = Job.getInstance(// configuration, // this.getClass().getSimpleName()// ); job.setJarByClass(this.getClass()); // 3: set job // input -> map -> reduce -> output // 3.1: input Path inPath = new Path(args[0]) ; FileInputFormat.addInputPath(job, inPath); // 3.2: mapper job.setMapperClass(WordCountMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class);// ===========================Shuffle====================================== // 1) partitioner// job.setPartitionerClass(cls); // 2) sort// job.setSortComparatorClass(cls); // 3) combine job.setCombinerClass(WordCountReducer.class); // 4) compress // set by configuration // 5) group// job.setGroupingComparatorClass(cls);// ===========================Shuffle====================================== // 3.3: reducer job.setReducerClass(WordCountReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); // set reducer number// job.setNumReduceTasks(3); // 3.4: output Path outPath = new Path(args[1]); FileOutputFormat.setOutputPath(job, outPath); // 4: submit job boolean isSuccess = job.waitForCompletion(true); return isSuccess ? 0 : 1 ; } public static void main(String[] args) throws Exception { // run job// int status = new WordCountMapReduce().run(args); // 1: get configuration Configuration configuration = new Configuration();// ===============================Compress===================================// configuration.set("mapreduce.map.output.compress", "true");// configuration.set(name, value);// ===============================Compress=================================== int status = ToolRunner.run(// configuration, // new WordCountMapReduce(), // args ) ; // exit program System.exit(status); }} 打包成为jar 包
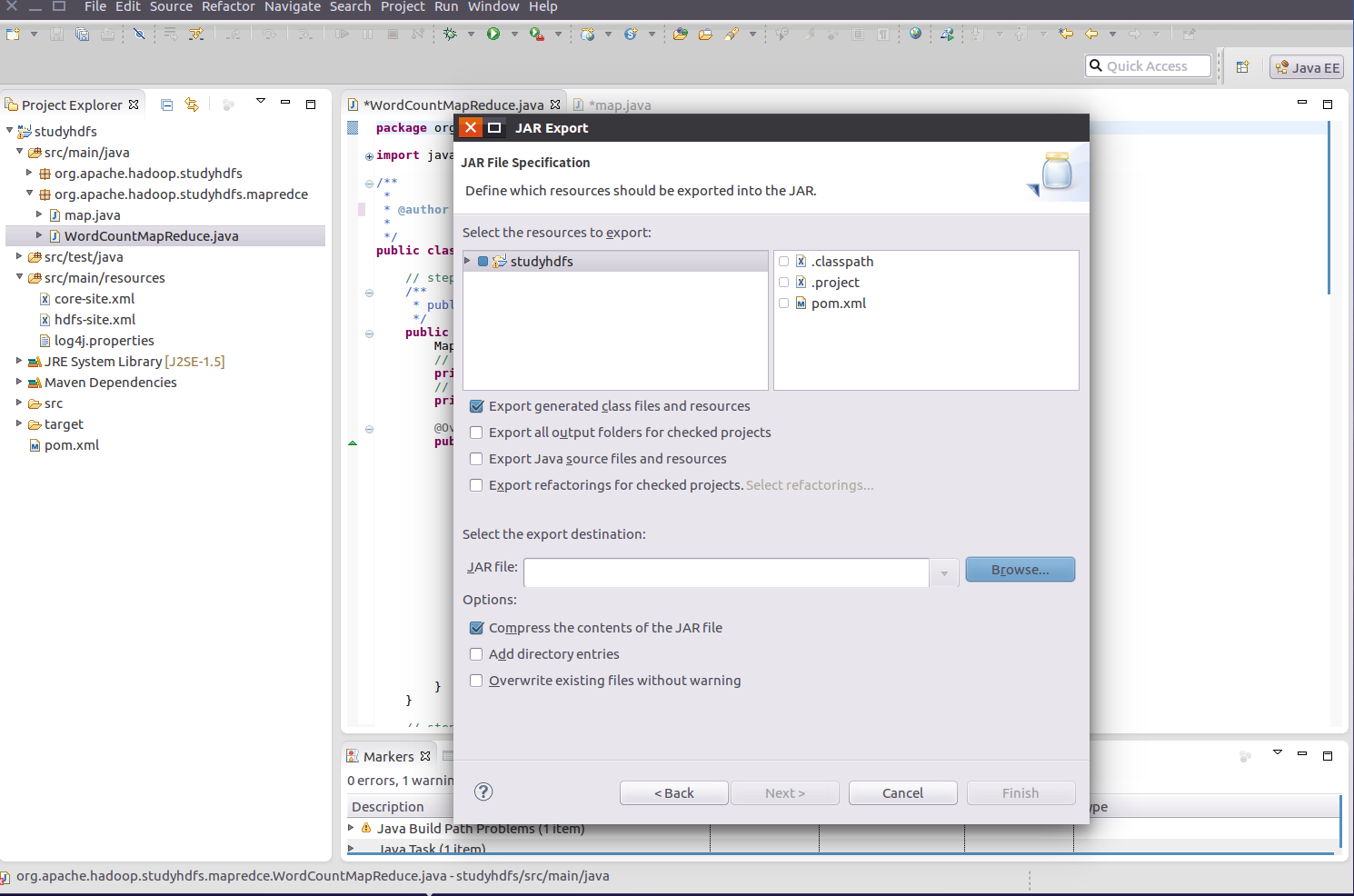
运行jar 包输出结果
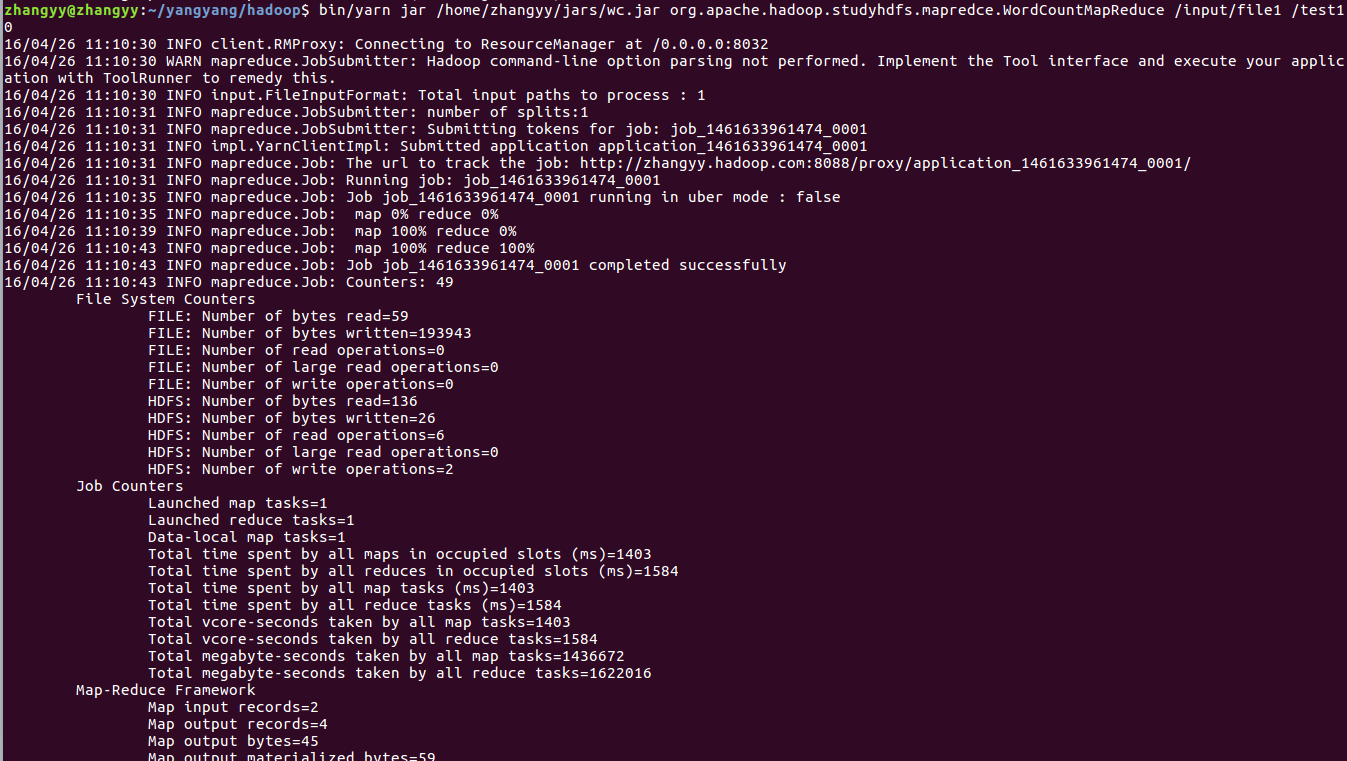
转载于:https://blog.51cto.com/flyfish225/2096593
你可能感兴趣的文章
查表法按日期生成流水号的示例.sql
查看>>
something about Google Mock / gmock使用小结
查看>>
pygame学习笔记(1)——安装及矩形、圆型画图
查看>>
让WebForm异步起来(转)
查看>>
jQuery UI Portlet 1.1.2 发布
查看>>
给字符数组赋值的方法
查看>>
Excel_replace
查看>>
Typescript Mixins(混合)
查看>>
C#Css/Js静态文件压缩--Yui.Compressor.Net
查看>>
配置tomcat的https通信(单向认证)
查看>>
Intellij Idea @Autowired取消提示
查看>>
httpclient调用https
查看>>
Oracle数据库中有关记录个数的查询
查看>>
sql语句查询出表里符合条件的第二条记录的方法
查看>>
题目1008:最短路径问题
查看>>
PHPExcel正确读取excel表格时间单元格(转载)
查看>>
继电器是如何成为CPU的
查看>>
分布式缓存
查看>>
Android-ViewPager+Fragment数据更新问题
查看>>
[WASM] Compile C Code into WebAssembly
查看>>